When I created my Raku programming language website with
Hugo static site generator, I had to manually create the syntax highlighted
html files for code examples shown in the front page, because Hugo used
Chroma(written in Go and uses a
mostly similar API to Pygments) for syntax highlighting which didn't
support Raku. So I opened an issue on Chroma, the discussion showed that you cannot just convert
the Raku lexer from Pygments to Chroma; You would need to create some functions manually, and
Chroma needed a new Emitter interface which would take the LexerState as an argument, because
Raku has some complex syntax; the Raku lexer in Pygments had functions for finding closing
brackets matching the opening brackets, and for regex nesting in tokens, regexes and
rules. In the end I realized functions for token nesting were unnecessary.
But I was curious if I could do something with the broken lexer I generated with the
pygments2chroma.py script that comes with Chroma. So I began working on the Raku lexer
without knowing Go, Chroma, Python or Pygments.
Chroma
After playing with the lexer for a while, I was very close to giving up. But after looking at the Chroma code and the functions it provided and also looking at some other lexers, I began to come up with some ideas.
For finding closing brackets I used the function generated by pygments2chroma and modified it a
lot and also as a workaround I placed empty capture groups inside the patterns that needed
bracket finding; and I filled those placeholders with the bracketsFinder function(or
mutator).
I also used a placeholder rule inside regex which would be replaced by bracketsFinder with the
appropriate rule which Poped from the regex state when the delimiter matched.
I did the same thing with POD formatters(C<code>, B<bold>,...), although I didn't have to,
and could create a state for each formatter that needed different tokens for highlighting.
I also created Emitters for Raku's colon pair syntax and POD config.
So I finally managed to create an imperfect Raku lexer for Chroma.
I added some things to Chroma itself as well; Added support for named
capture groups(although there is something people need to watch
for. regexp2, the regex package Chroma uses, implements .Nets' regex
engine which doesn't maintain the order of captures, in other words,
the number capturing groups come first then named capturing groups are
appended, which I found surprising, and made a pull
request to add an option
for maintaining the capture order (I don't know if it'll get merged),
added the ByGroupNames helper function, and made the emitter
functions take *LexerState as argument, so they have access to more
things.
I should have done these things before I made the Raku lexer, so I could use them while I was making it, but at the time, I didn't know I could do it! And also improved the Svelte, SCSS and Fish lexers. Additionally, added two new styles, doom-one and doom-one2 which are inspired by Atom One and Doom Emacs's Doom One themes. You can use them in version 0.9.2.
Lastly, the things I learned Chroma command line tool can do(which of course you can find by
running chroma --help):
Printing syntax highlighted files to terminal:
chroma -f terminal256 -s doom-one source.raku
Generating SVG file:
chroma -s doom-one source.raku --svg > output.svg
Generating styled HTML files:
chroma -s doom-one --html --html-all-styles --html-lines source.raku > output.html
You can install Chroma with:
go install github.com/alecthomas/chroma@latest
Or if you use Arch Linux, you can install it from AUR.
Generate images from source code with Germanium
Germanium(written in Go) is an alternative to
Silicon, which is written in
Rust and uses Syntect which
uses Sublime Text syntax definitions for syntax
highlighting, which does not support Raku. Syntax definitions are written in
YAML files, I don't know if you can put logic in there. Also they
say they don't accept new packages! Maybe
Syntect accepts packages in their submodule? I don't know.
Anyway, I added support for options choosing a style and also listing styles. Also changed the Chroma version in the dependencies, so new lexers and styles can be used in Germanium v1.2.0.
Generating images:
germanium -s doom-one -o output.png source.raku
You can install Germanium with:
go install github.com/matsuyoshi30/germanium@latest
Or if you use Arch Linux, you can install it from AUR.
Golang
While writing the lexer, I often felt frustrated, because I wanted some functionality and would search for it and find three things:
- A GitHub issue with a proposal for what I wanted, which would be a closed issue and not implemented
- A Stack Overflow answer which said: you can do it with "this long and manually written code"
- A Stack Overflow answer which said: you can emulate it like this
Which made me make a joke about it.
Go, to me is the complete opposite of Raku. And yet even though I didn't like it and the frustration that came with it, strangely I began to kinda like it! I contributed to different Go projects in a relatively short time, that says something nice about Go. So I may actually try to learn it. Even though I see this when I visit their website(because of Google App Engine and sanctions! Google usually goes to the extreme).
Lastly, there are things the go command line tool doesn't provide(or maybe I'm unaware of it).
Such as updating all modules installed globally(especially useful for
command line apps).
Hugo and my blog
My blog was generated by Jekyll until now. I don't blog often, so I didn't have much motivation to migrate to Hugo, even though Hugo has more features. But I said what the heck, I created a lexer that Hugo uses so I might as well use it. Therefore, I migrated my blog to Hugo and even used some of its features, for example I created categories and tags, added TOC and used the markdown render hooks feature for headings to linkify them and images to linkify them to their sources which is useful when the image is large.
Raku lexer is available since Hugo v0.84.0.
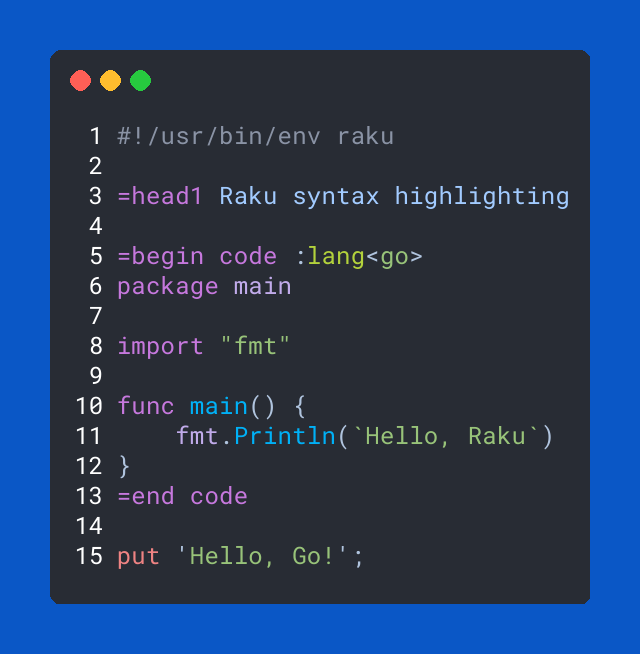
Raku
Finally some syntax highlighting for Raku inside Hugo with random code from here and there:
#!/usr/bin/env raku
=head1 Raku syntax highlighting
=begin code :lang<go>
package main
import "fmt"
func main() {
fmt.Println(`Hello, Raku`)
}
=end code
put 'Hello, Go!';
#`(
multi
line
comment
)
say qq「some $scalar text」;
say qww「some $variable 'some other text' text」;
say q:ww「some $variable 'some other text' text」;
say q:w「some $variable 'some other text' text」;
say qq:w「some $variable 'some other text' text」;
say Q:c「some $variable 'some text' { 2 + 1 } text」;
say q:a「some @array[1] 'some text' { 2 + 1 } text」;
say Q:a:c「some @array 'some text' { 2 + 1 } text」;
say Q[some \qq[$variable.method()] testing];
say 'some \qq[$variable.method()] testing';
say "some @array[2] %hash{'test'} $variable.method() func() testing";
use Some::Module:auth<author>:ver(v1.*.0+);
say X::SomeException;
#| B<Fibonacci> with multiple dispatch
multi sub fib (0 --> 0) {}
multi sub fib (1 --> 1) {}
multi sub fib (\n where * > 1) {
fib(n - 1) + fib(n - 2)
}
say fib 10;
# OUTPUT: 55
# Indirect invocant
notes $trip: "Almost there";
LABEL:
for <a b c> {
.put;
}
# Roles and classes
role Shape {
method area { ... }
method print_area {
say "Area of {self.^name} is {self.area}.";
}
}
class Rectangle does Shape {
has $.width is required;
has $.height is required;
method area {
$!width * $!height
}
}
Rectangle.new(width => 5, height => 7).print_area;
# OUTPUT: Area of Rectangle is 35.
#| U<INI> Parser
grammar INIParser {
token TOP { <block> <section>* }
token section { <header> <block> }
token header { '[' ~ ']' \w+ \n+ }
token block { [<pair> | <comment>]* }
rule pair { <key> '=' <value> }
token comment { ';' \N* \n+ }
token key { \w+ }
token value { <-[\n ;]>+ }
}
my $match = INIParser.parse: q:to/END/;
; Comment
key1=value1
key2 = value2
; Section 1
[section1]
key3=value3
END
say $match<block><pair>[0]<value>;
# OUTPUT: 「value1」
say $match<section>[0]<block><pair>[0]<value>;
# OUTPUT: 「value3」
grammar Calculator {
token TOP { <calc-op> }
proto rule calc-op {*}
rule calc-op:sym<add> { <num> '+' <num> }
rule calc-op:sym<sub> { <num> '-' <num> }
token num { \d+ }
}
class Calculations {
method TOP ($/) { make $<calc-op>.made; }
method calc-op:sym<add> ($/) { make [+] $<num>; }
method calc-op:sym<sub> ($/) { make [-] $<num>; }
}
say Calculator.parse('2 + 3', actions => Calculations).made;
# OUTPUT: «5»
grammar G {
rule TOP { <function-define> }
rule function-define {
'sub' <identifier>
{
say "func " ~ $<identifier>.made;
make $<identifier>.made;
}
'(' <parameter> ')' '{' '}'
{ say "end " ~ $/.made; }
}
token identifier { \w+ { make ~$/; } }
token parameter { \w+ { say "param " ~ $/; } }
}
G.parse('sub f ( a ) { }');
# OUTPUT: «func fparam aend f»
# Inifinite and lazy list
my @fib = 0, 1, * + * ... ∞;
say @fib[^11];
# OUTPUT: (0 1 1 2 3 5 8 13 21 34 55)
# Feed operator
@fib[^20] ==> grep(&is-prime) ==> say();
# OUTPUT: (2 3 5 13 89 233 1597)
# Function composition
my &reverse_primes = &reverse ∘ &grep.assuming(&is-prime);
say reverse_primes ^20;
# OUTPUT: (19 17 13 11 7 5 3 2)
my @a = 1..4;
my @b = 'a'..'d';
# Zip two lists using Z meta operator
say @a Z @b;
# OUTPUT: ((1 a) (2 b) (3 c) (4 d))
say @a Z=> @b;
# OUTPUT: (1 => a 2 => b 3 => c 4 => d)
# Hyper Operators
say @b «~» @a;
# OUTPUT: [a1 b2 c3 d4]
# Junctions
say 'Find all the words starting with a lowercase vowel'.words.grep: *.starts-with: any <a e i o u>;
# OUTPUT: (all a)
ay '🦋'.chars;
# OUTPUT: 1
say '🦋'.codes;
# OUTPUT: 1
say '🦋'.encode.bytes;
# OUTPUT: 4
my $raku = 'راکو';
say $raku.chars;
# OUTPUT: 4
say $raku.uninames;
# OUTPUT: (ARABIC LETTER REH ARABIC LETTER ALEF ARABIC LETTER KEHEH ARABIC LETTER WAW)
say $raku.comb;
# OUTPUT: (ر ا ک و)
say +$raku.comb;
# OUTPUT: 4
subset ℕ of Int where * > 0;
sub f (ℕ $a, ℕ $b --> Array of ℕ) {
Array[ℕ].new: $a², $b²;
}
say f 1,2;
# OUTPUT: [1 4]
# Native Types
my int @a = ^10_000_000;
say [+] @a;
# OUTPUT: 49999995000000
sub MAIN(
Str $file where *.IO.f = 'file.dat', #= an existing file to frobnicate
Int :size(:$length) = 24, #= length/size needed for frobnication
Bool :$verbose, #= required verbosity
) {
say $length if $length.defined;
say $file if $file.defined;
say 'Verbosity ', ($verbose ?? 'on' !! 'off');
}
# $ script-name
# Usage:
# script-name [--size|--length=<Int>] [--verbose] [<file>]
# [<file>] an existing file to frobnicate
# --size|--length=<Int> length/size needed for frobnication
# --verbose required verbosity
# Using NativeCall to access libnotify and show a notification
use NativeCall;
sub notify_init (str $appname --> int32) is native('notify') { * }
sub notify_uninit is native('notify') { * }
class NotifyNotification is repr('CPointer') { * }
sub notify_notification_new (str $summary, str $body, str $icon --> NotifyNotification) is native('notify') { * }
sub notify_notification_show (NotifyNotification) is native('notify') { * }
if notify_init 'MyApp' {
notify_notification_show notify_notification_new 'My Notification', 'Notification Body', Str;
notify_uninit;
}
# Concurrency
react {
my $current-proc;
whenever $script.watch.unique(:as(*.path), :expires(1)) {
.kill with $current-proc;
$current-proc = Proc::Async.new($*EXECUTABLE, $script);
my $done = $current-proc.start;
whenever $done {
$current-proc = Nil;
}
}
}
my $modules-load = start @files
.grep(/ \.(yaml|yml) $/)
.sort(-*.s)
.race(batch => 1, degree => 6)
.map(-> $file {
my $yaml = self!load-yaml($file, $schema, $problems);
with $yaml {
Easii::Model::Module.new(parsed => $yaml, source => $file.basename)
}
})
.eager;
# Supply
my $bread-supplier = Supplier.new;
my $vegetable-supplier = Supplier.new;
my $supply = supply {
whenever $bread-supplier.Supply {
emit("We've got bread: " ~ $_);
};
whenever $vegetable-supplier.Supply {
emit("We've got a vegetable: " ~ $_);
};
}
$supply.tap(-> $v { say "$v" });
$vegetable-supplier.emit("Radish");
# OUTPUT: «We've got a vegetable: Radish»
$bread-supplier.emit("Thick sliced");
# OUTPUT: «We've got bread: Thick sliced»
$vegetable-supplier.emit("Lettuce");
# OUTPUT: «We've got a vegetable: Lettuce»
=finish
Goodbye!